
Gallery
Workflows allow for the composition of software and data.
Workflows allow software configuration and input parameters and option sweeping when deploying workloads.
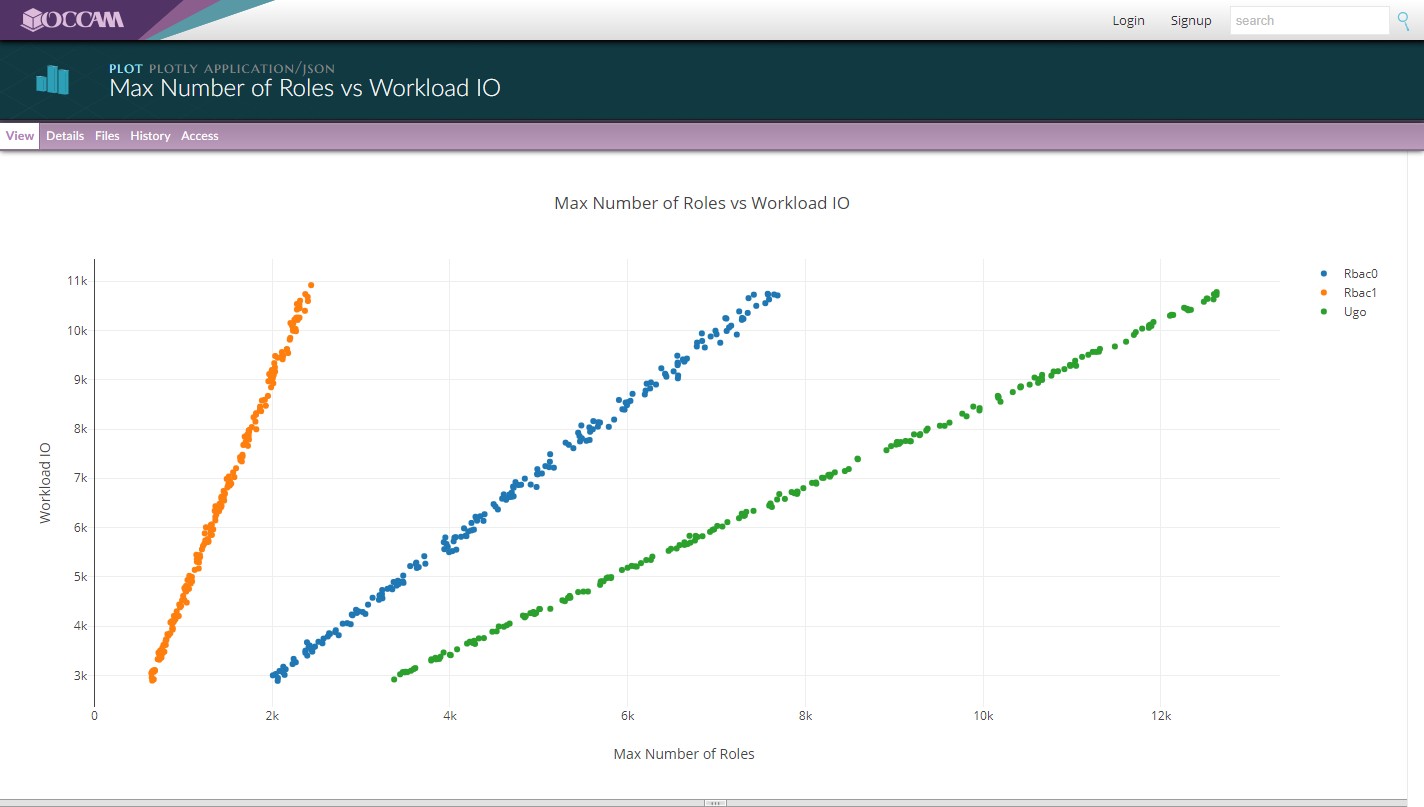
Widgets can be added by anyone to render data in different ways which are not actually part of Occam itself. Here, a Plotly widget gives us an interactive plot.
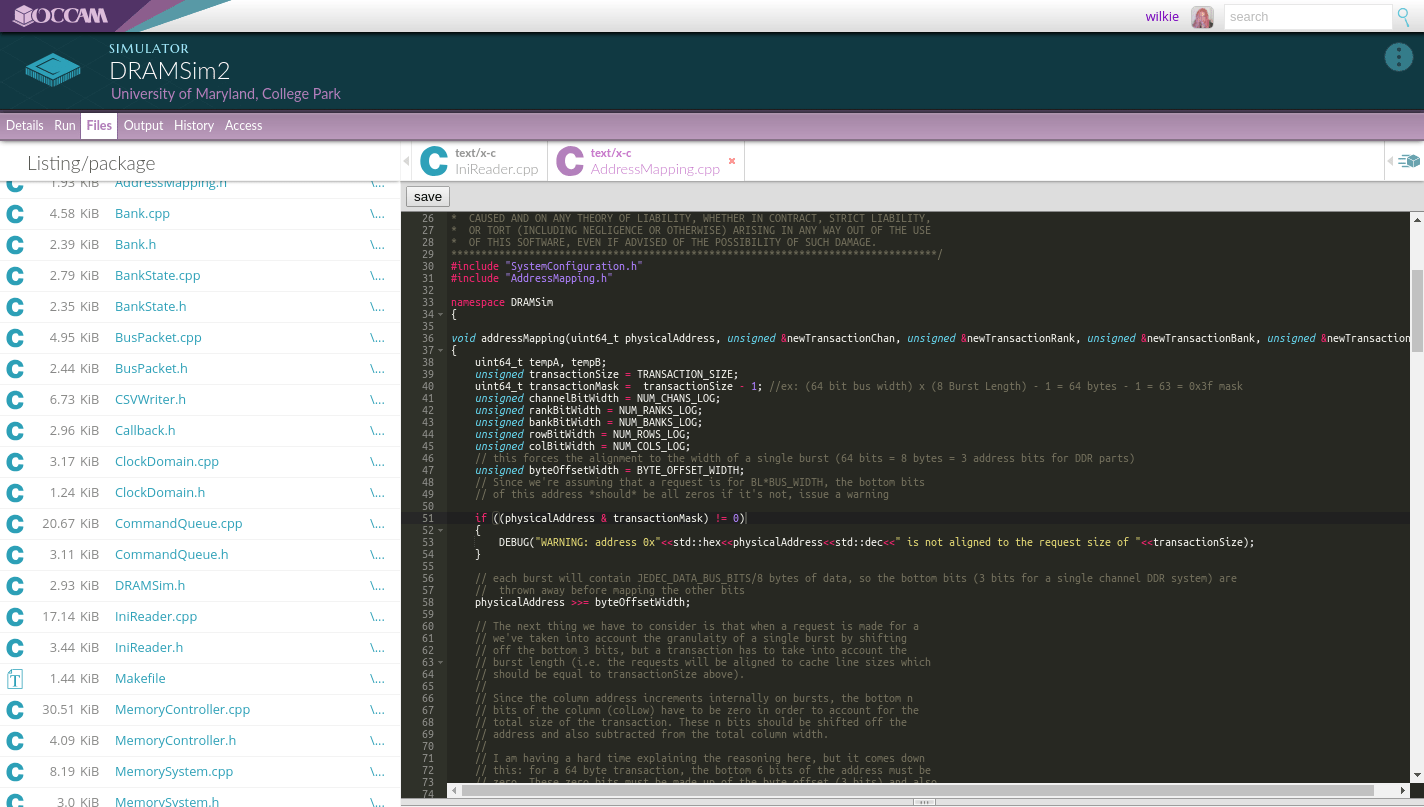
You can edit files and code within each object and compile them without using a terminal, but rather by using editing widgets, such as this text editor.
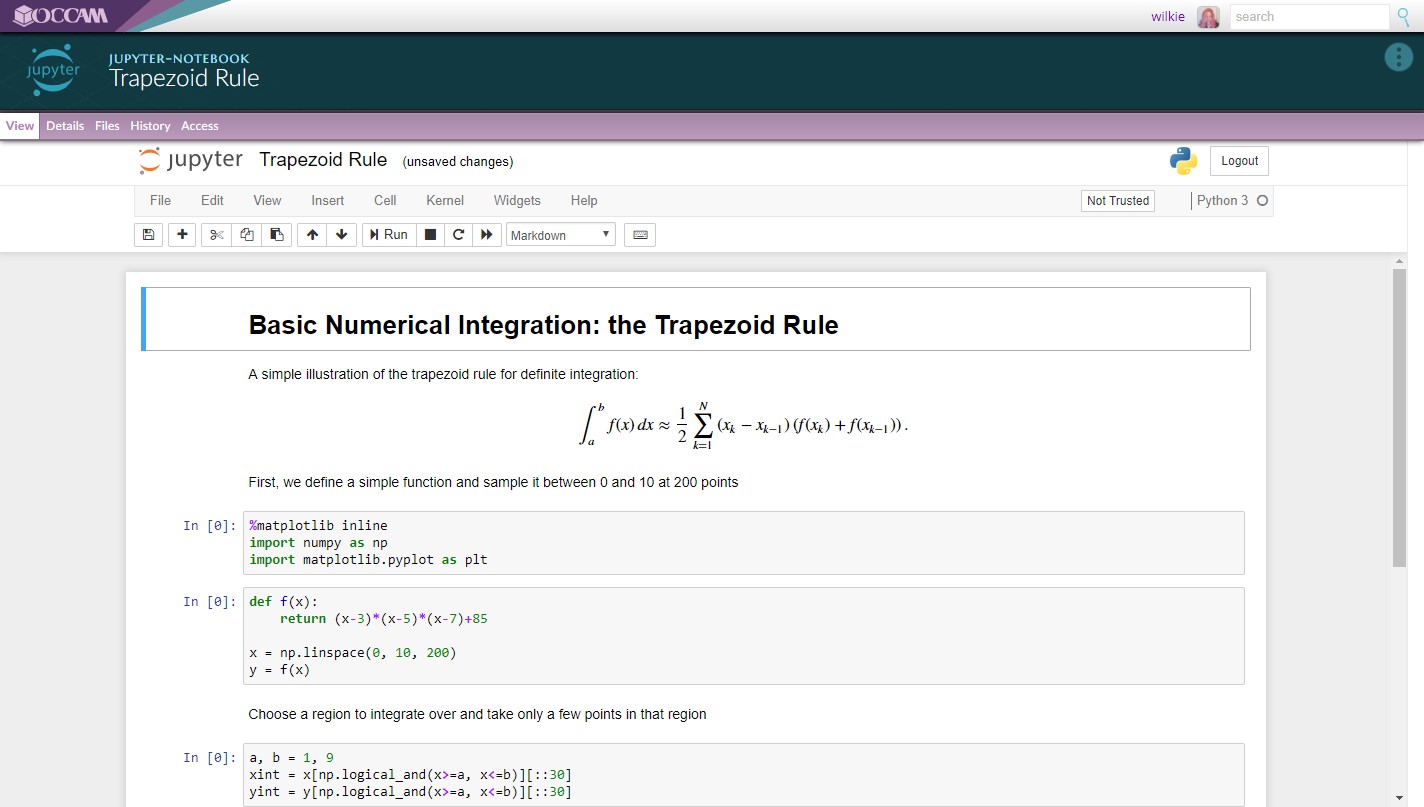
We handle the preservation and execution of server applications such as JupyterLab in order to preserve Python-based Jupyter Notebooks.
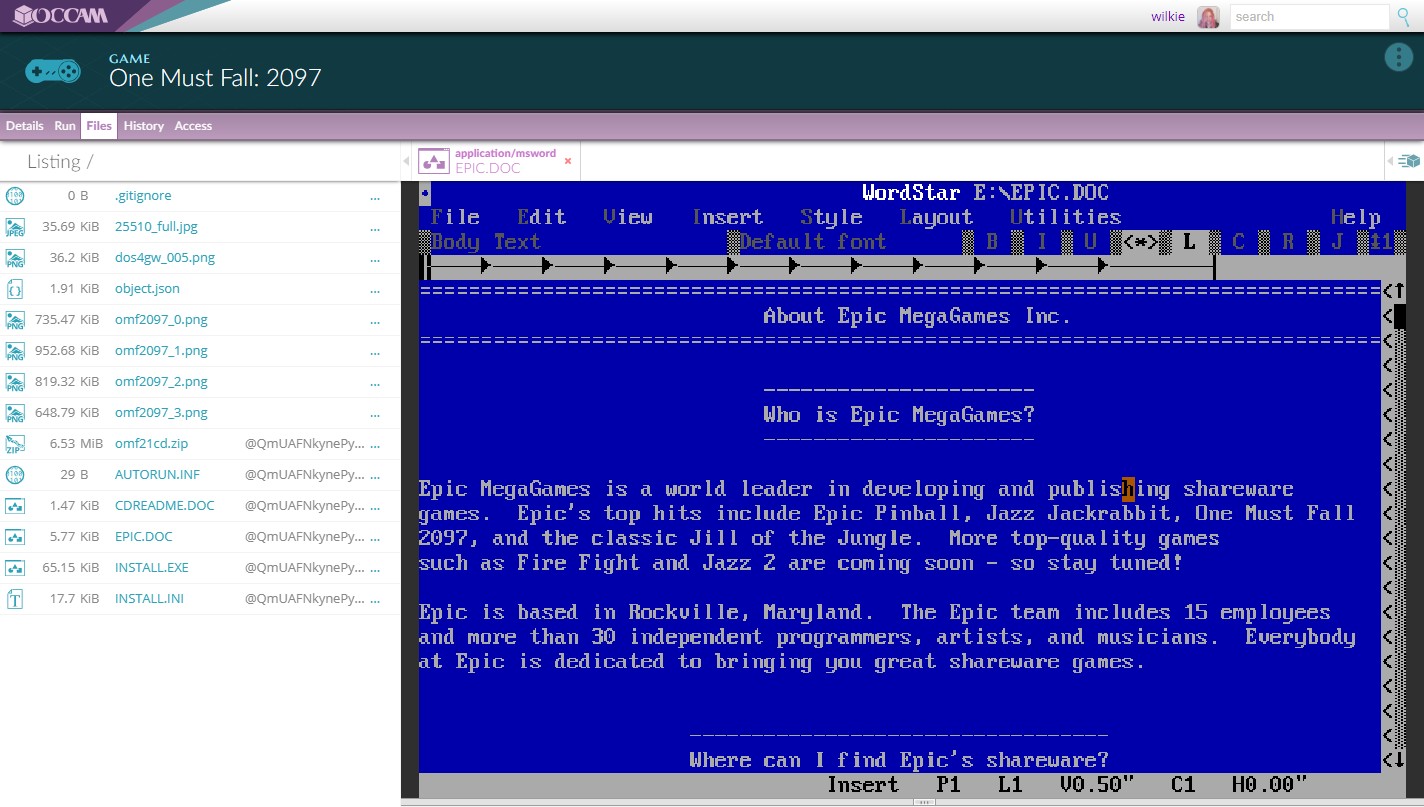
There is support for running obsolete applications in JavaScript emulators to allow for exploration of older data. How long until we need such a technique for data we regularly use today?
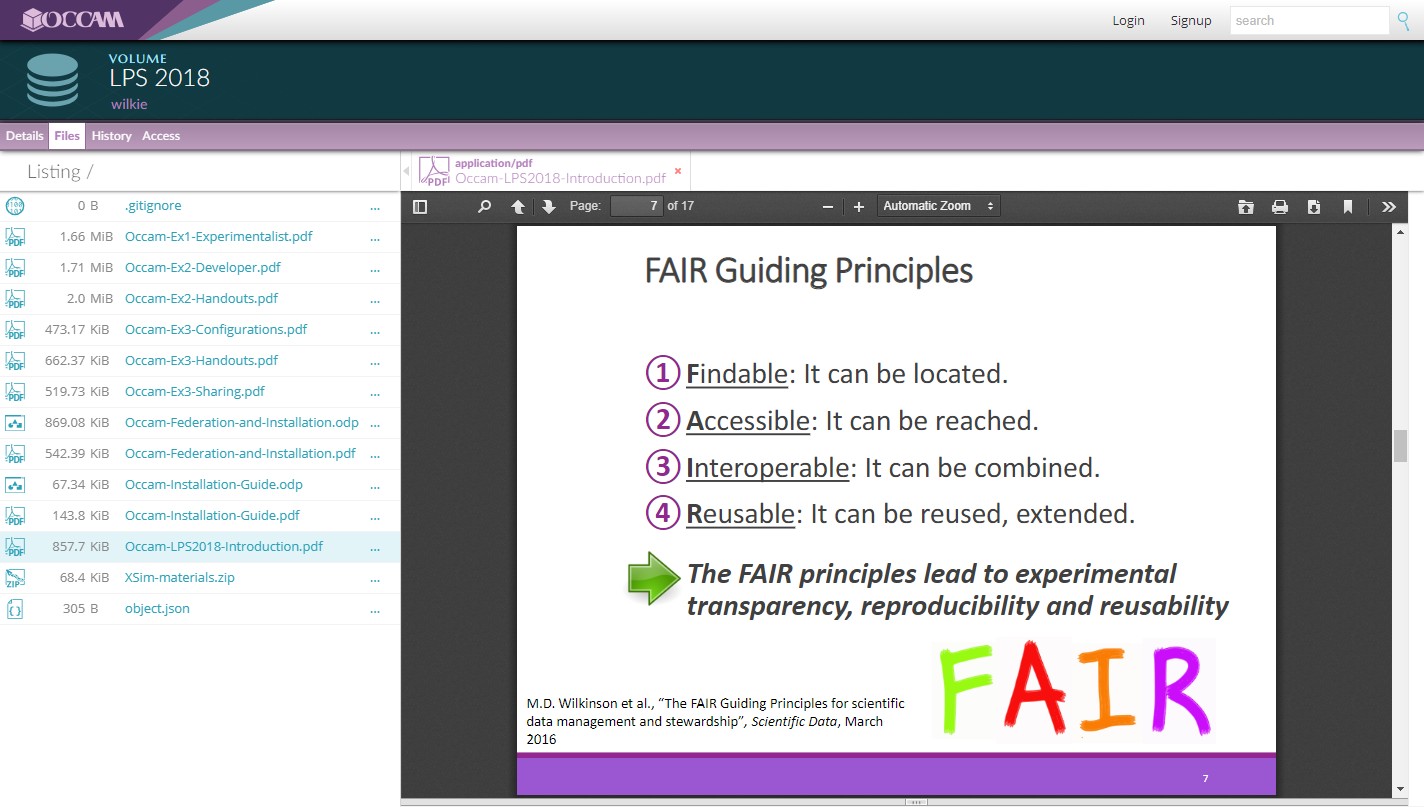
This PDF viewer is yet another widget. This PDF.js software is an archived object itself. The Occam system does not have this functionality built in, meaning anybody can add support for other formats at any time.
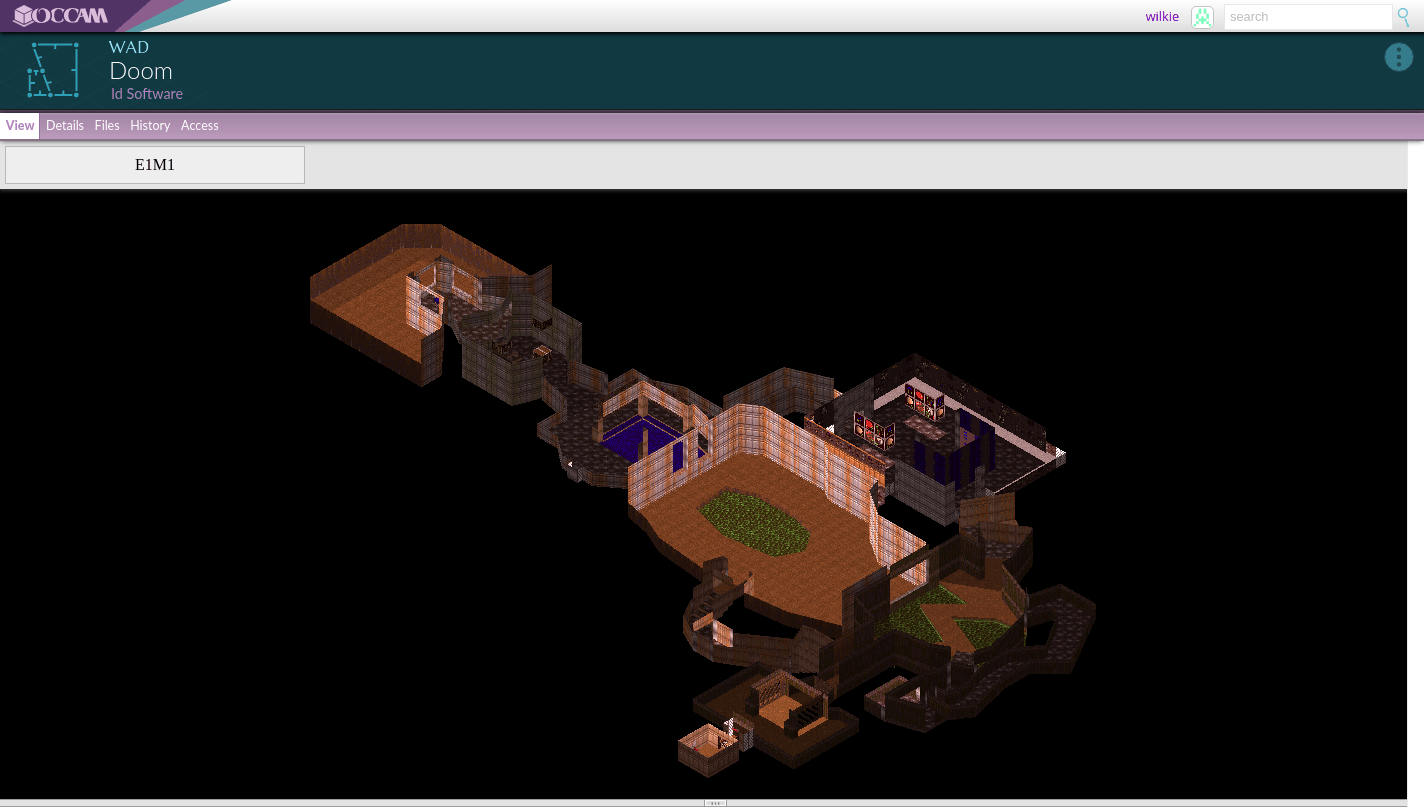
Some widgets may offer new ways of interacting with content. You could play this Doom level, but you can also just view it with a JavaScript viewer.
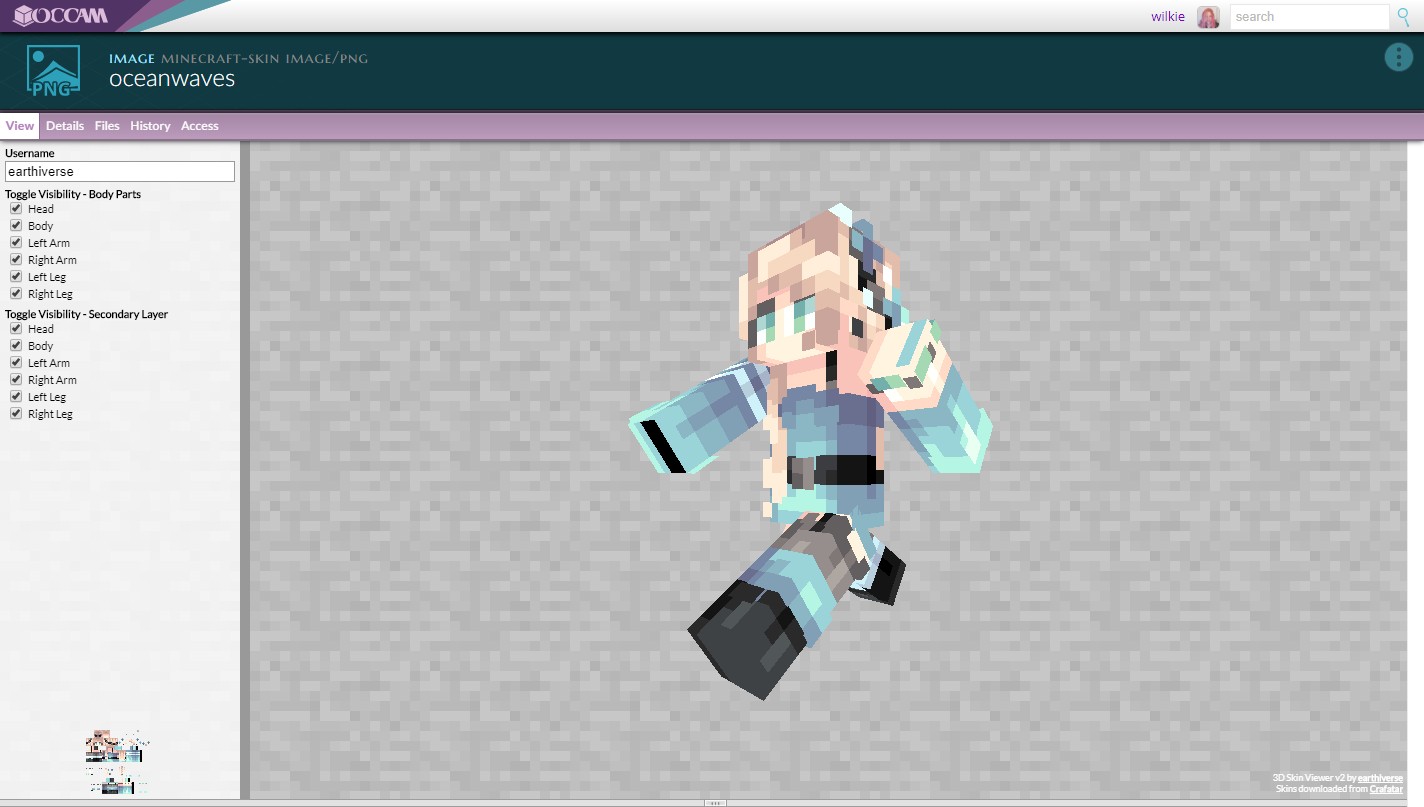
This is an example of the power of widgets being associated as a viewer. This Minecraft skin viewer widget has associated itself with certain tagged images, which otherwise are just normal PNG files.
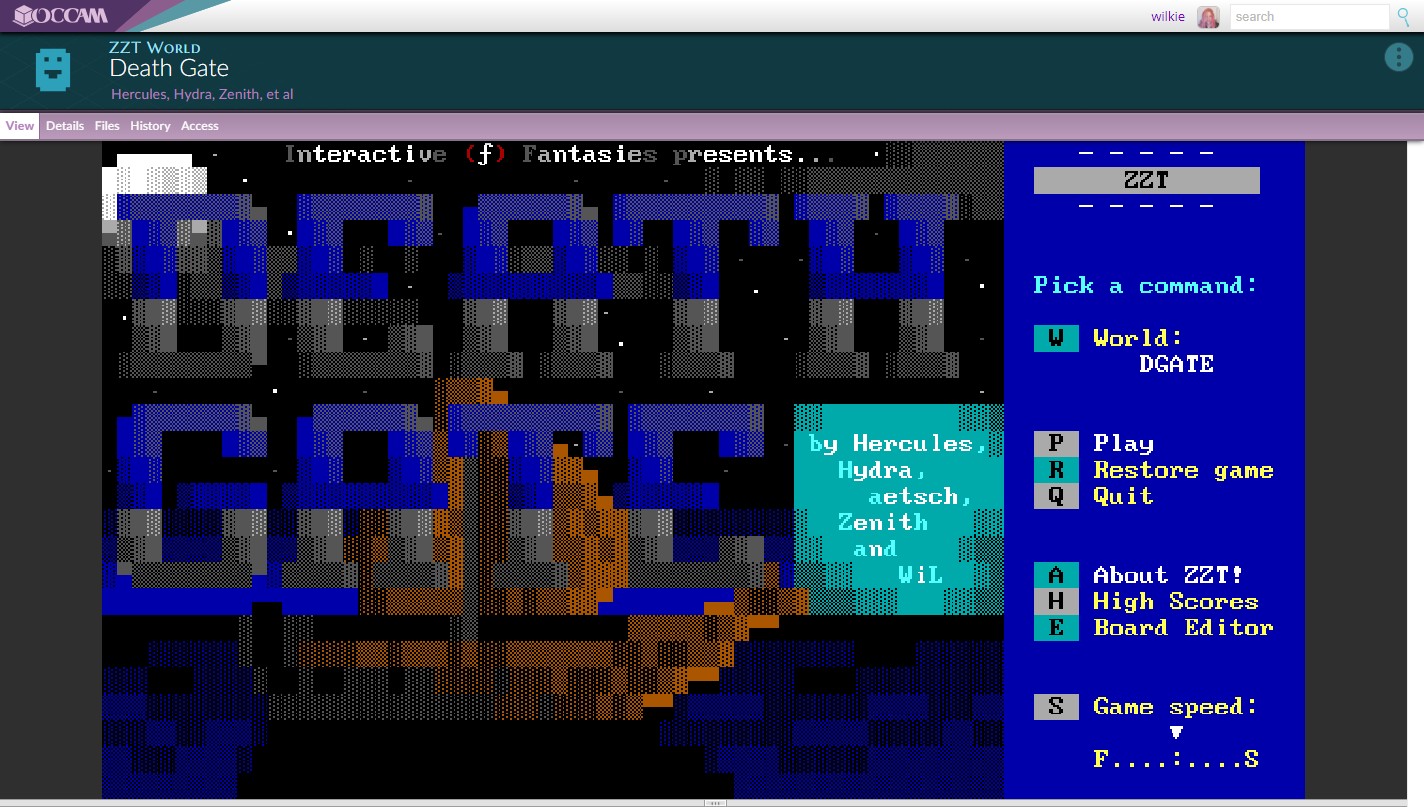
Interactive art is not left out as well. Here, a community created level pack for the game ZZT can be played by creating a virtual machine with several objects: an emulator, ZZT itself, and the level pack. This is determined automatically.
More Specifically...
Software Curation
Computing and programming is still a young discipline. Over time, software can functionally deteriorate before the data is can read or manage becomes obsolete. In the sciences, this degradation can influence the repeatability and reproducibility of computational results. To this end, Occam serves as a digital software and data archive built for the very demanding and delicate needs of scientific work, but also general enough to cover the equally important software preservation needs of the arts and humanities.
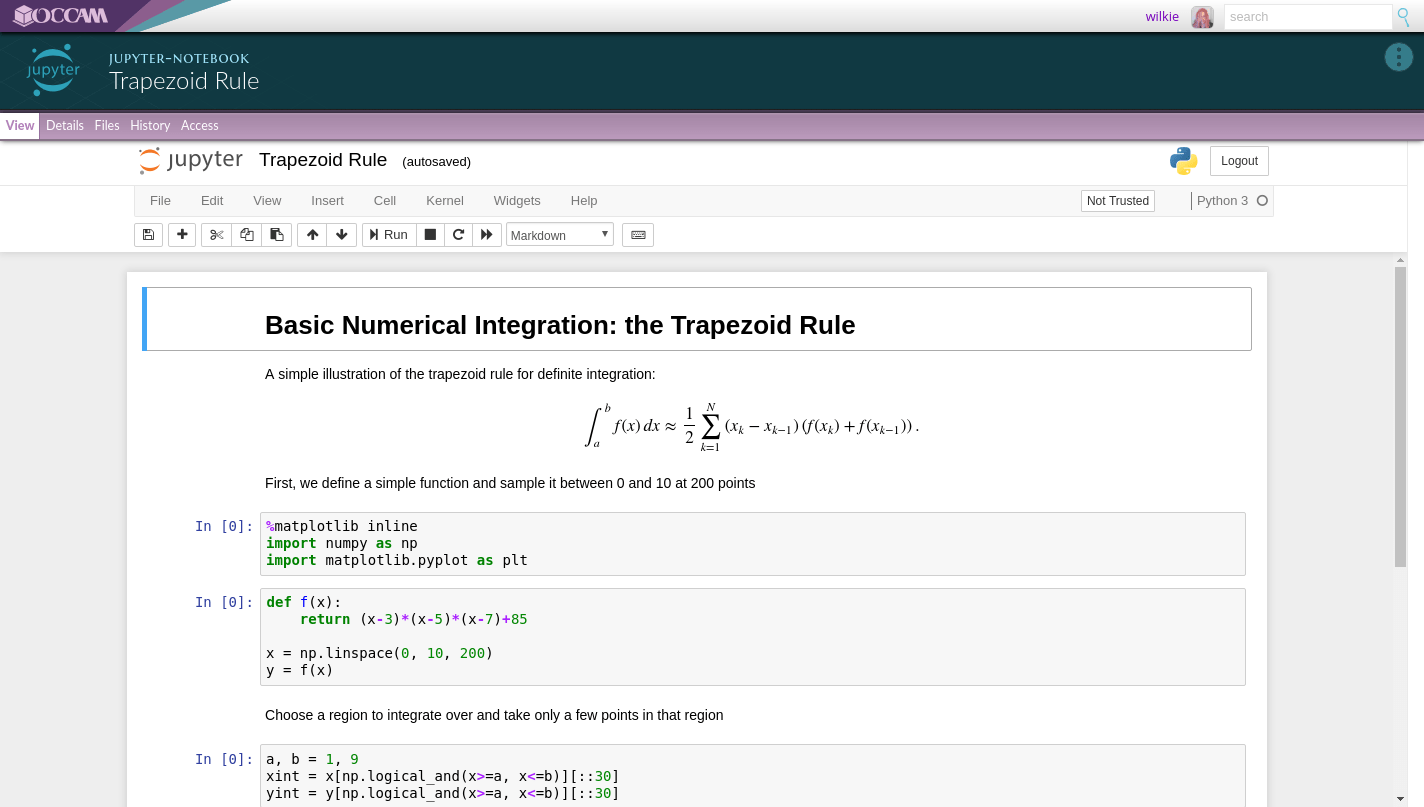
Interactive Lab Notebooks, such as Jupyter, fit right in. Occam can preserve them by preserving the ability to run Jupyter Hub, and run a Jupyter web service on the server that can be loaded within the Occam website.

Taking a deeper look at this notebook, we see what metadata is preserved. This includes the dependencies required by this notebook.
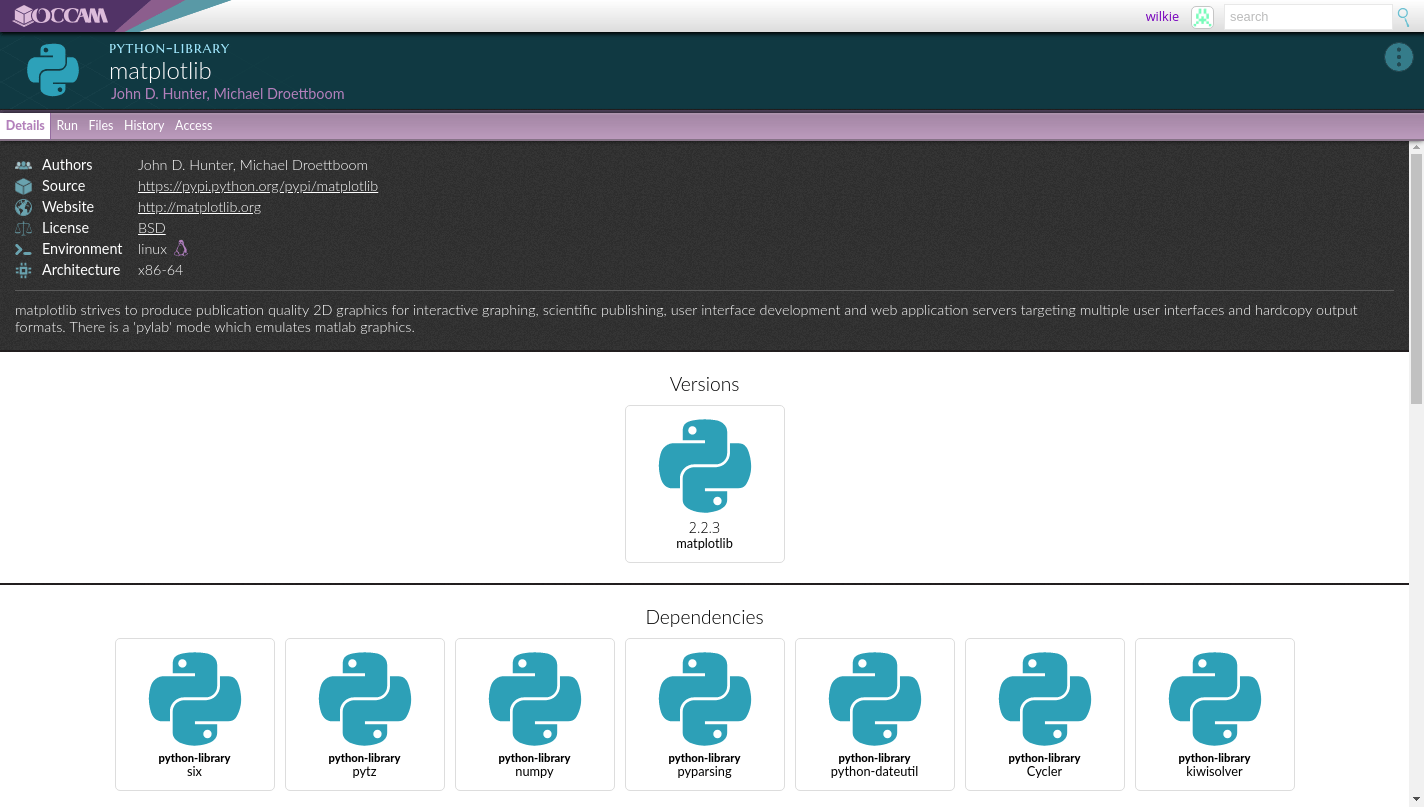
Looking at one particular dependency, matplotlib, which is stored as its own separate object within the system. Others can use this without duplication.
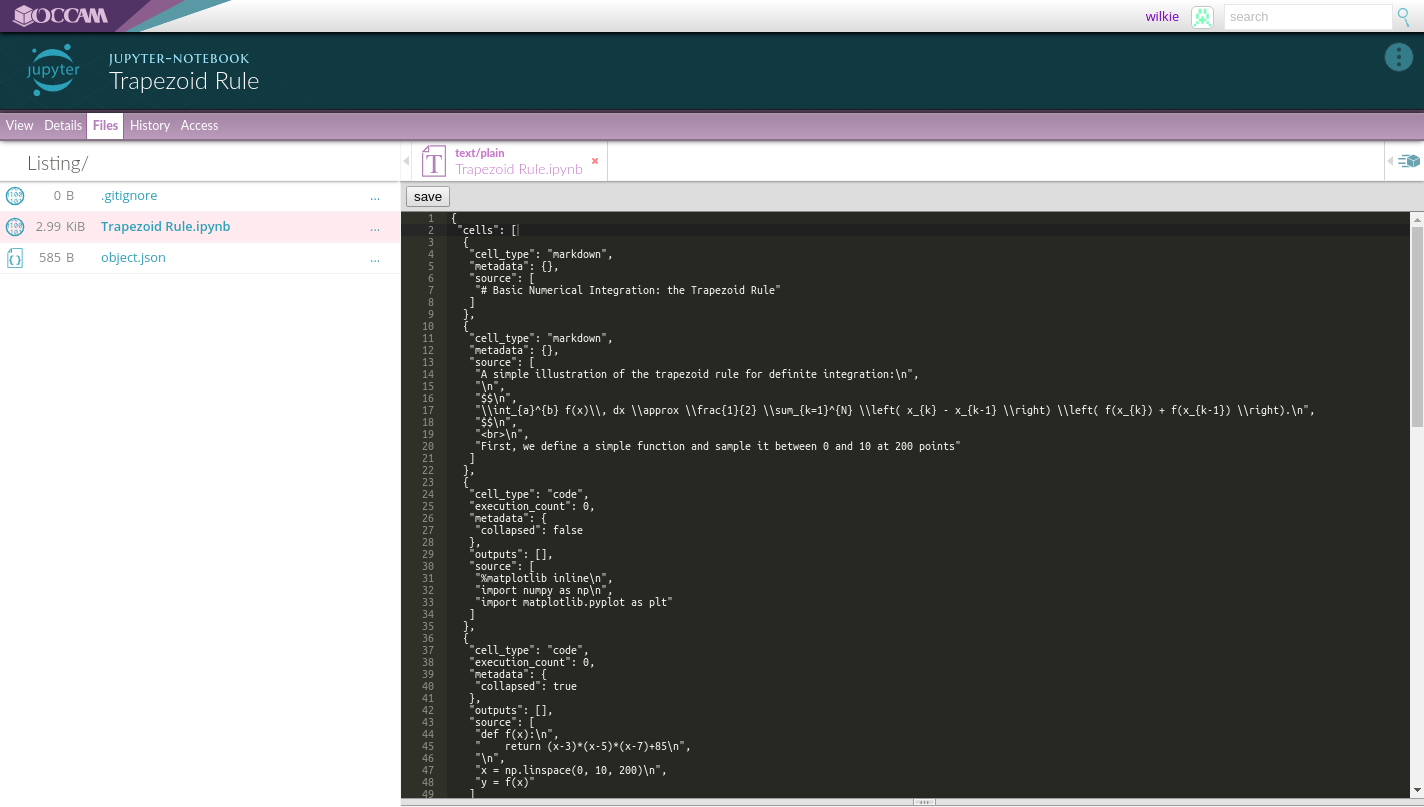
Within any curated object, you can view the file listing. You can open or view any individual file with any software resource on the system. The Ace editor, in this case.
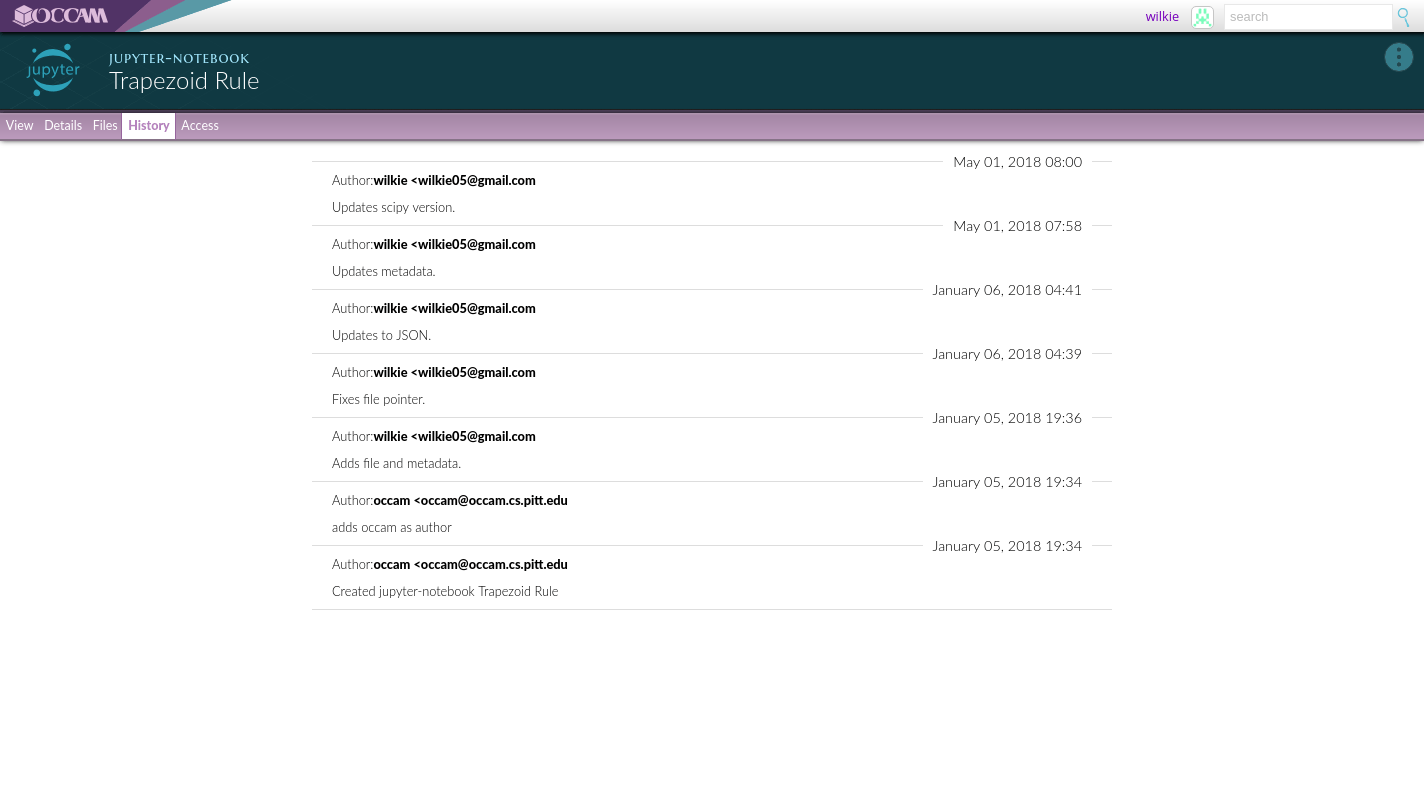
All objects are versioned. You can investigate the history of any object and, to answer Cher, you certainly can "turn back time" and view an object at an earlier point.
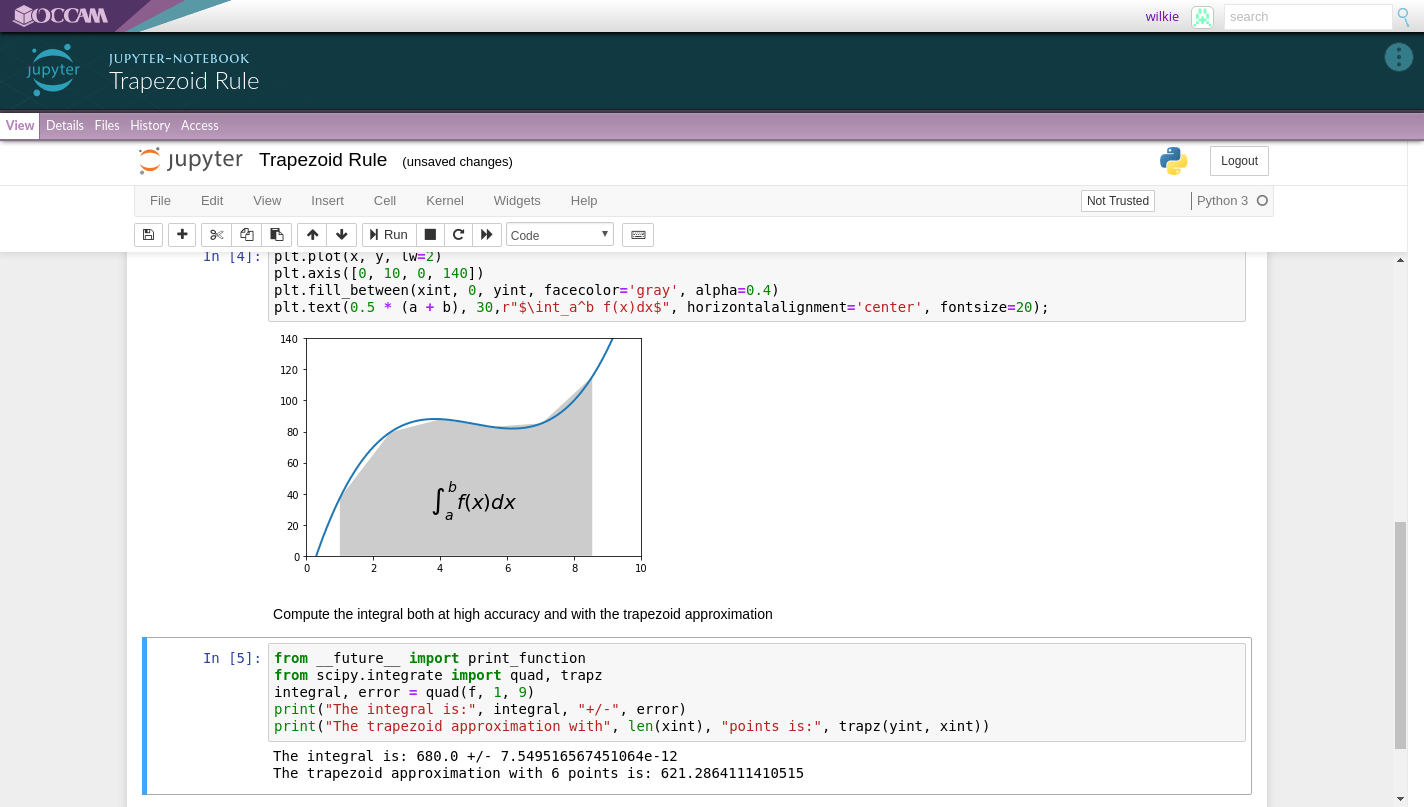
At the end of the day, what we do is make sure things run. Here is another view of the notebook being viewed in the browser. The JupyterLab server software is being executed on the backend.
Occam takes objects, such as simulator code, from the ephemeral Internet and migrates them to reside within the federated curated space. Once an object is installed onto a node, that node immediately becomes a mirror for any and all resources used to build that object.
Build/Compile Repeatability
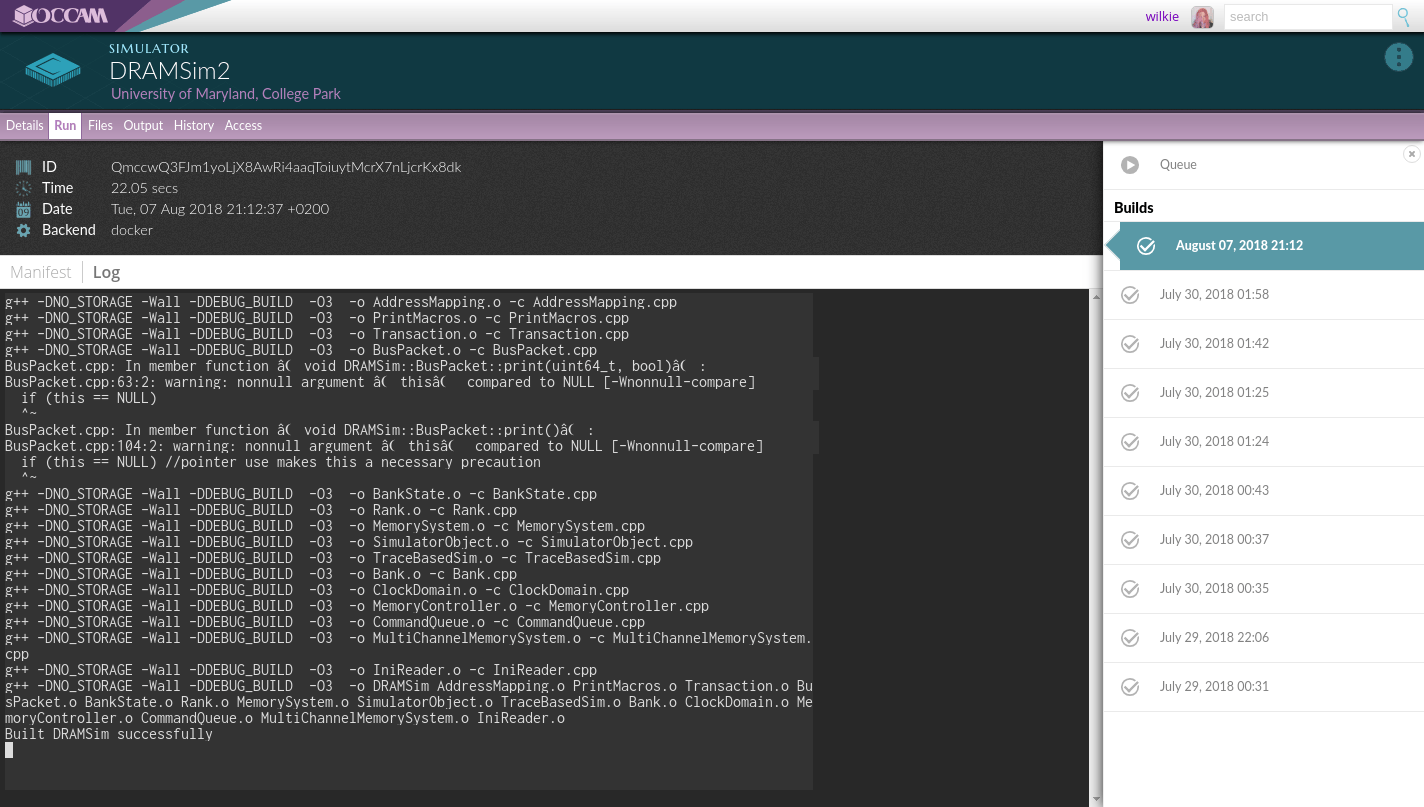
Here, we can see the log that was recorded when this simulator was built. We can also look at other previous builds. We can ask ourselves, was there any deviation?
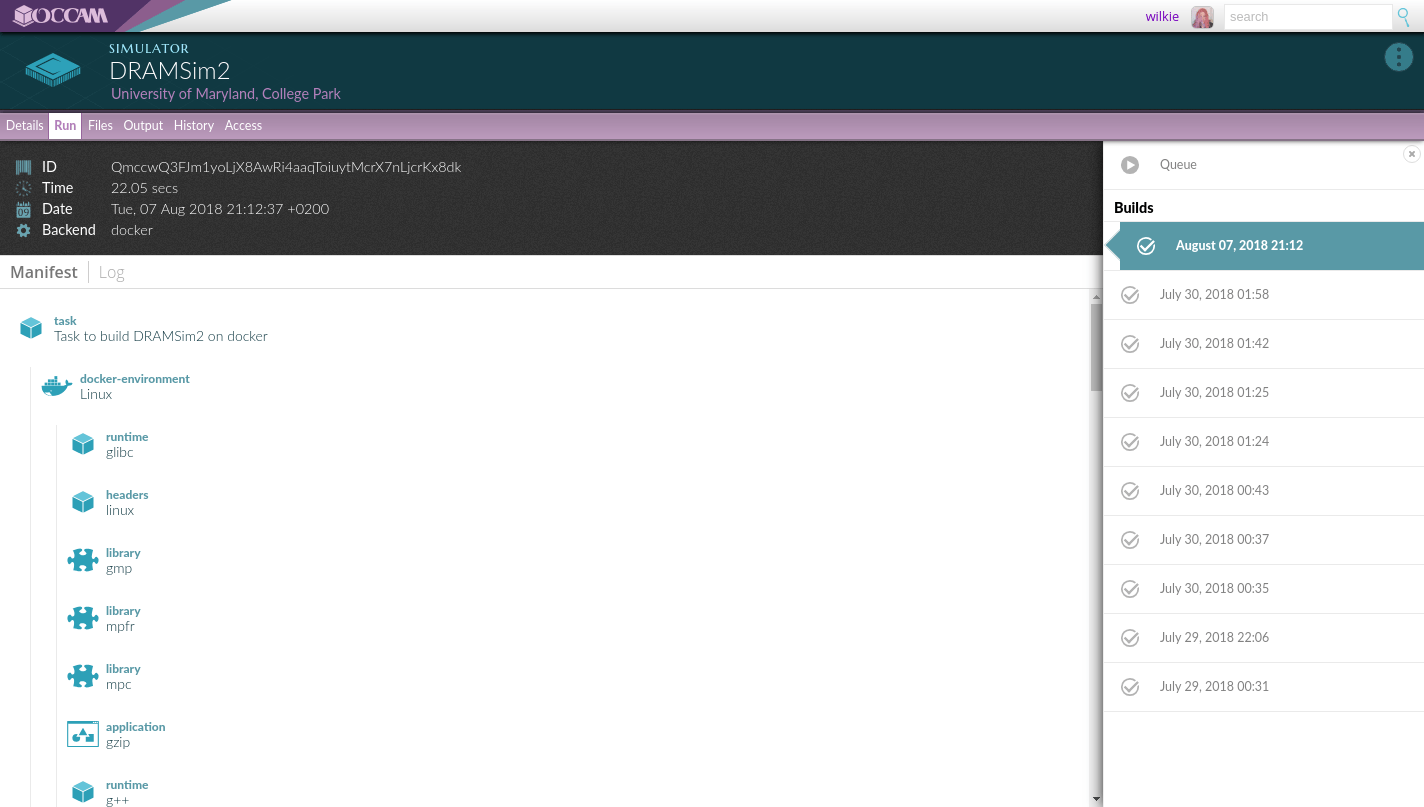
Similarly, we can see the provenance of the built software by investigating the contents of the Virtual Machine that was historically used to build it. We can ask, was anything used that has a known problem?
When an object is built, a virtual environment is created. Any requests that the object's build process uses to pull in other extraneous files or repositories will be captured and recorded such that they are also mirrored.
Adaptive Preservation
Interactive Lab Notebooks, such as Jupyter, fit right in. Occam can preserve them by preserving the ability to run Jupyter Hub, and run a Jupyter web service on the server that can be loaded within the Occam website.
With the WAD viewer, even if you cannot run Doom (which is unlikely, honestly!) you can view the level in another widget. Perhaps somebody adds a level editor eventually?
Interactive art is not left out as well. Here, a community created level pack for the game ZZT can be played by creating a virtual machine with several objects: an emulator, ZZT itself, and the level pack. This is determined automatically.
When the execution of software is requested, the system will generate a virtual machine based on the current native environment and the capabilities available. For instance, it may run some software reasonably natively within a container. However, in the future, it may decide to run the same software on a virtual machine or emulator. This graceful degradation keeps software running longer.
Widgets and Data Extensibility
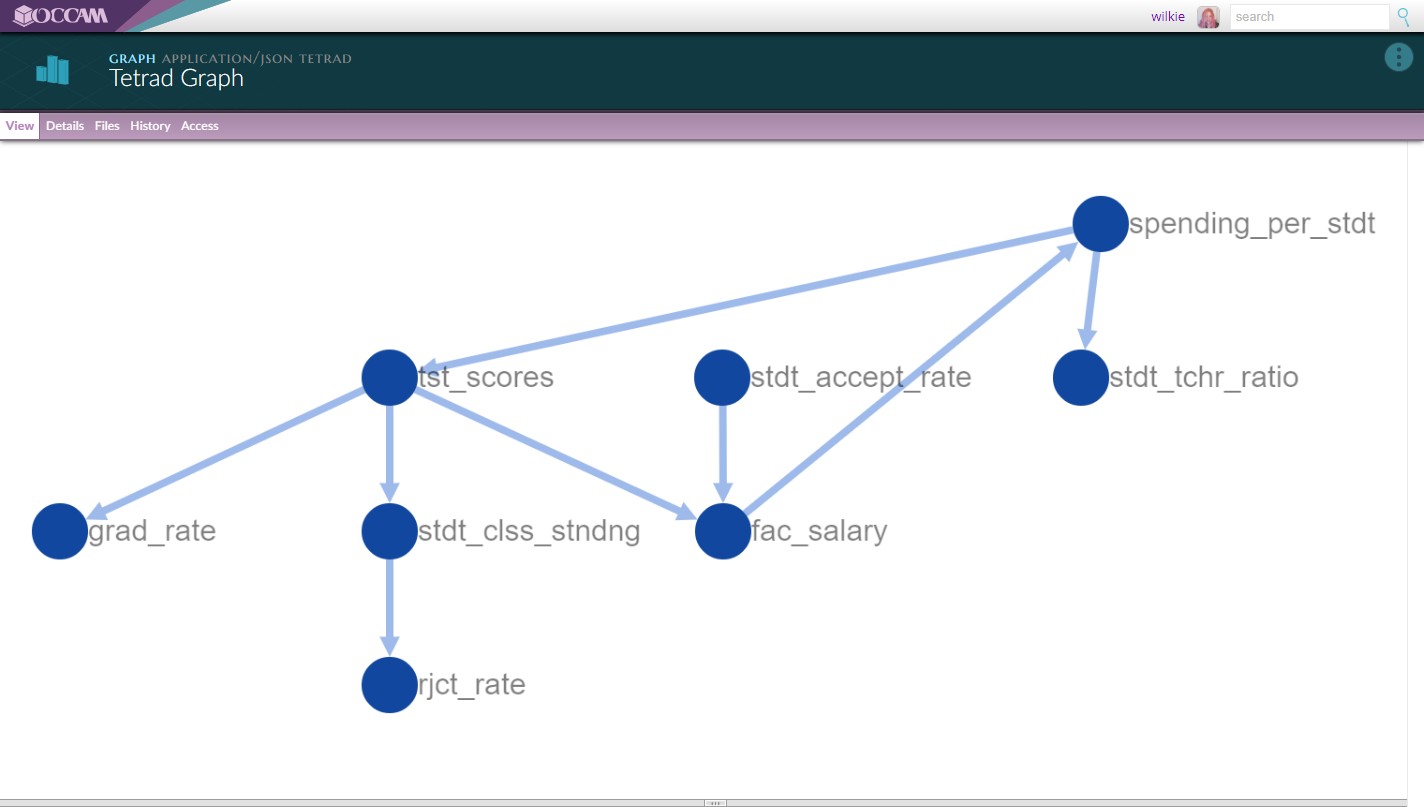
This is a graph widget for a specialized graph format from a mostly bespoke tool. This widget only took around an hour to develop.
Widgets can be added by anyone to render data in different ways which are not actually part of Occam itself. Here, a Plotly widget gives us an interactive plot.
This PDF viewer is yet another widget. This PDF.js software is an archived object itself. The Occam system does not have this functionality built in, meaning anybody can add support for other formats at any time.
You can also add 'editing' widgets. The most generic of which is the Ace Editor widget, which is associated with text files. Of course, you can associate any widget as an editor. Do you want to edit your code with WordStar? To each their own!
This is an example of the power of widgets being associated as a viewer. This Minecraft skin viewer widget has associated itself with certain tagged images, which otherwise are just normal PNG files.
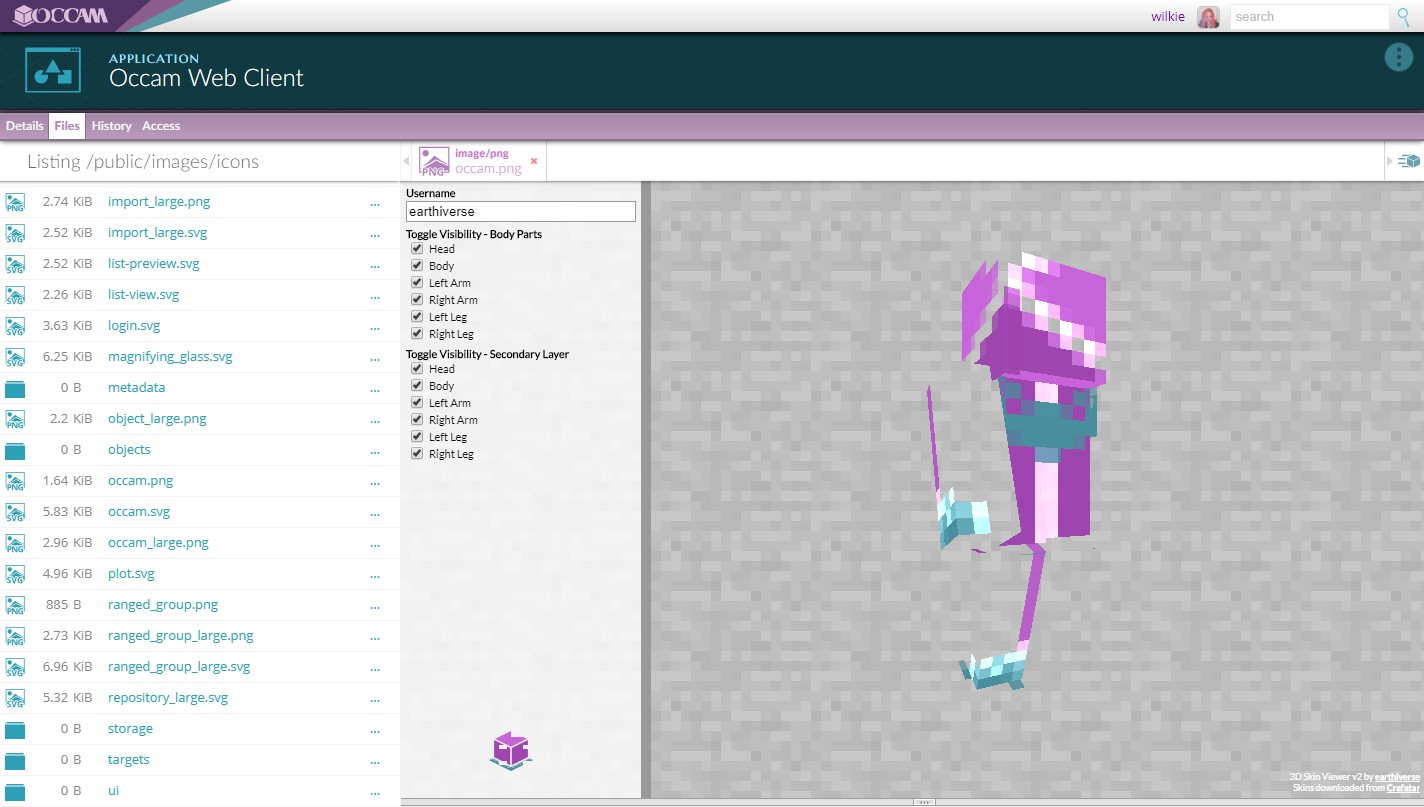
Of course, we can open any image file, even if it is untagged, with any widget we should choose. Here we can open the Occam logo in the Minecraft skin viewer. It kind of works! It's all about reuse. It's all about exploration.
Digital obsolescence is the failure to read or render data due to the lack of available software. To stave off this type of degradation, Occam allows the association of software to particular formats or object types. One interesting inclusion is the ability to target browsers as the runtime environment. That is, JavaScript widgets can be developed and used within the system to interact with data the same as any other more traditional software.
Access and Discoverability
One issue, particularly with scientific research software, is that tools are often underutilized. They are written for a particular purpose and, although not always intended, often go unused. These bespoke tools often overlap in ability and purpose suggesting a lack of discoverability. To stave off this concern, Occam is built with search in mind. Objects have types which relate themselves to data and other objects that may interact with them. Also, there is a faceted search mechanism to help filter out the exact set of software that is relevant.
Workflows and Composability
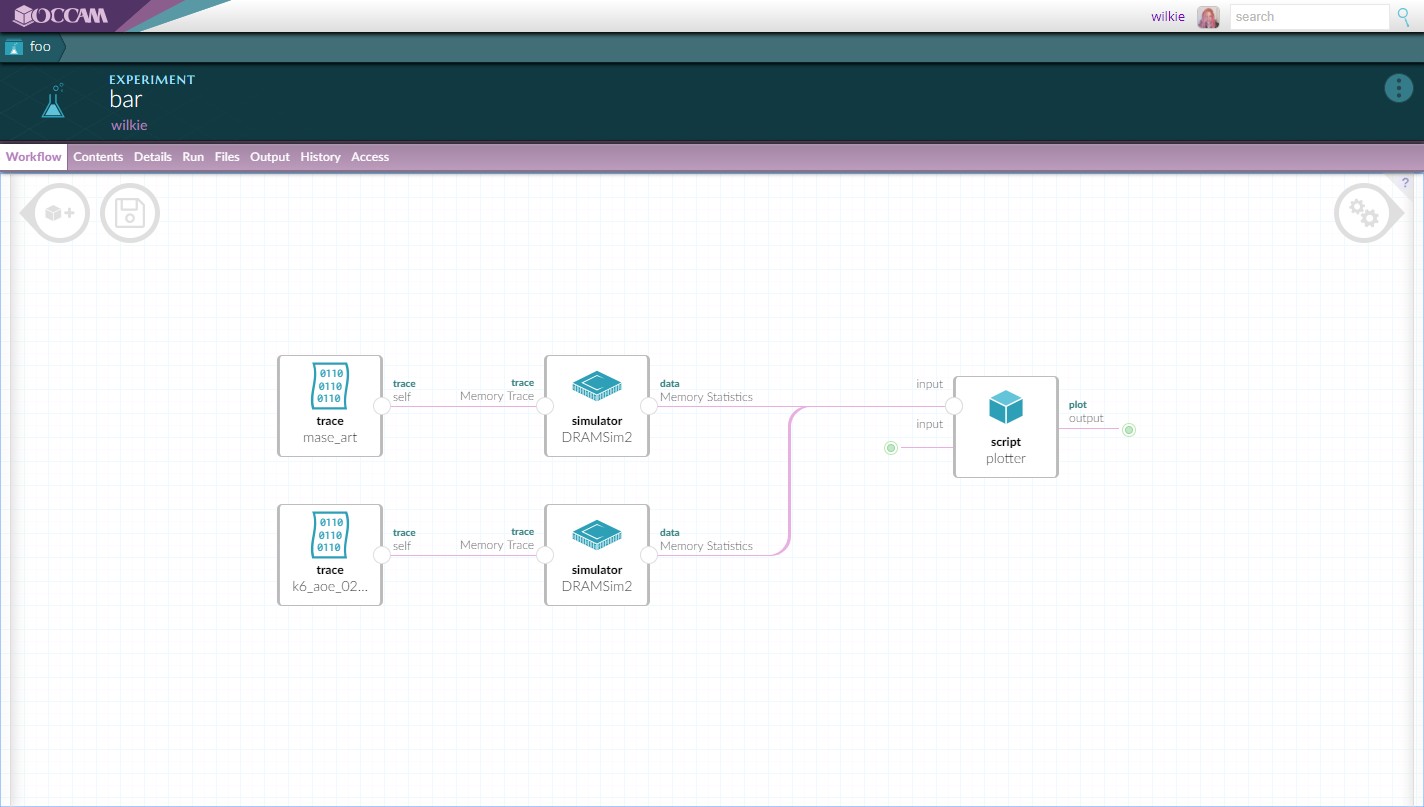
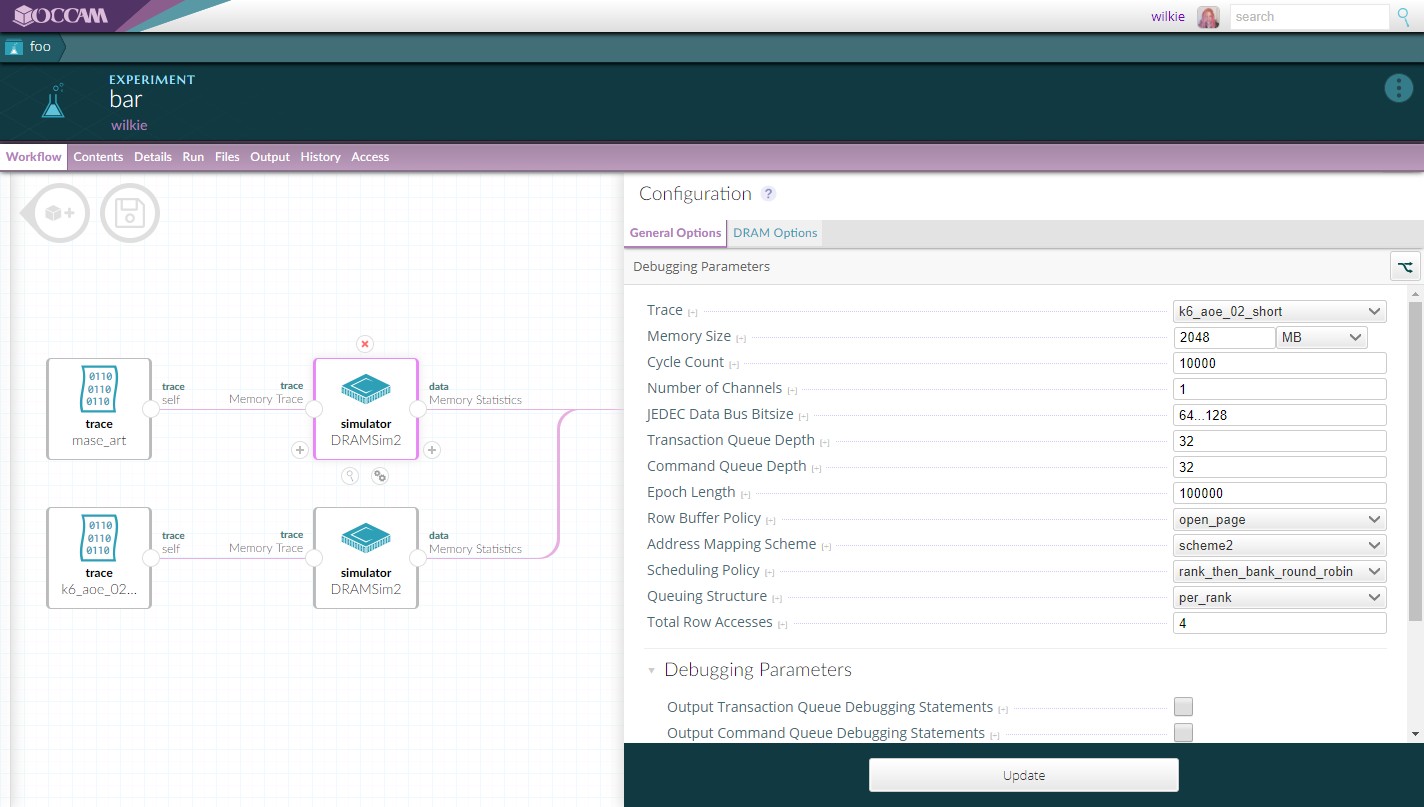
In order to faciliate the proper composition of different software tools, Occam provides a graphical editor to stitch together a workflow. You simply connect each artifact together in this editor and the system can execute the overall apparatus automatically. Also provided is a configuration editor which provides a consistent way of updating and varying parameters for each node. This makes it easy to explore a variety of outcomes by providing a value range in any of these configuration options, which will generate a run for each permutation.
Workflows allow for the composition of software and data. Here we have several different traces being consumed by DRAMSim2, a DRAM memory simulator, aggregating into a script that generates our plot.
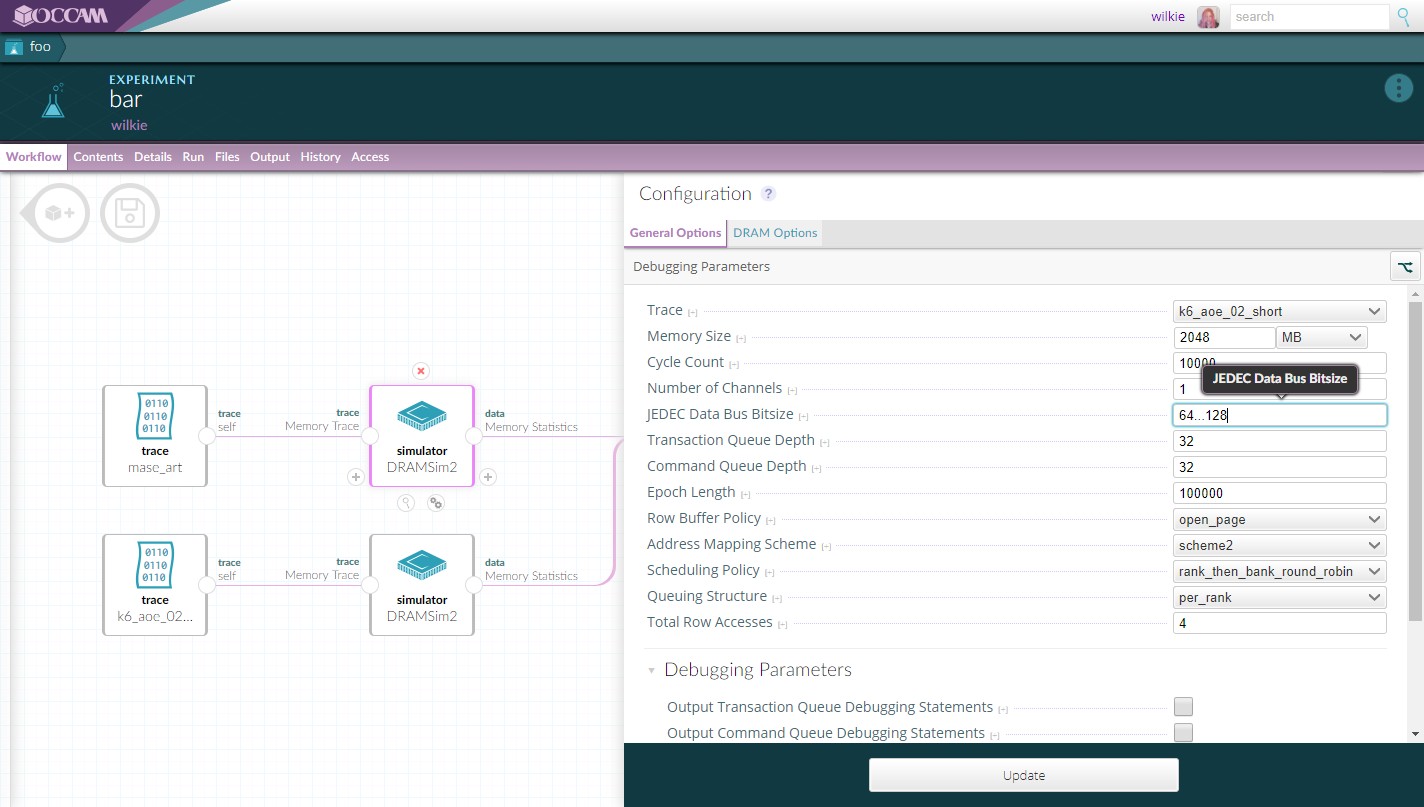
Each node in a workflow represents some piece of data or executable software. Each can provide a schema to generate a configuration form. This lets people interact with input parameters in a manner which is the same for every object.
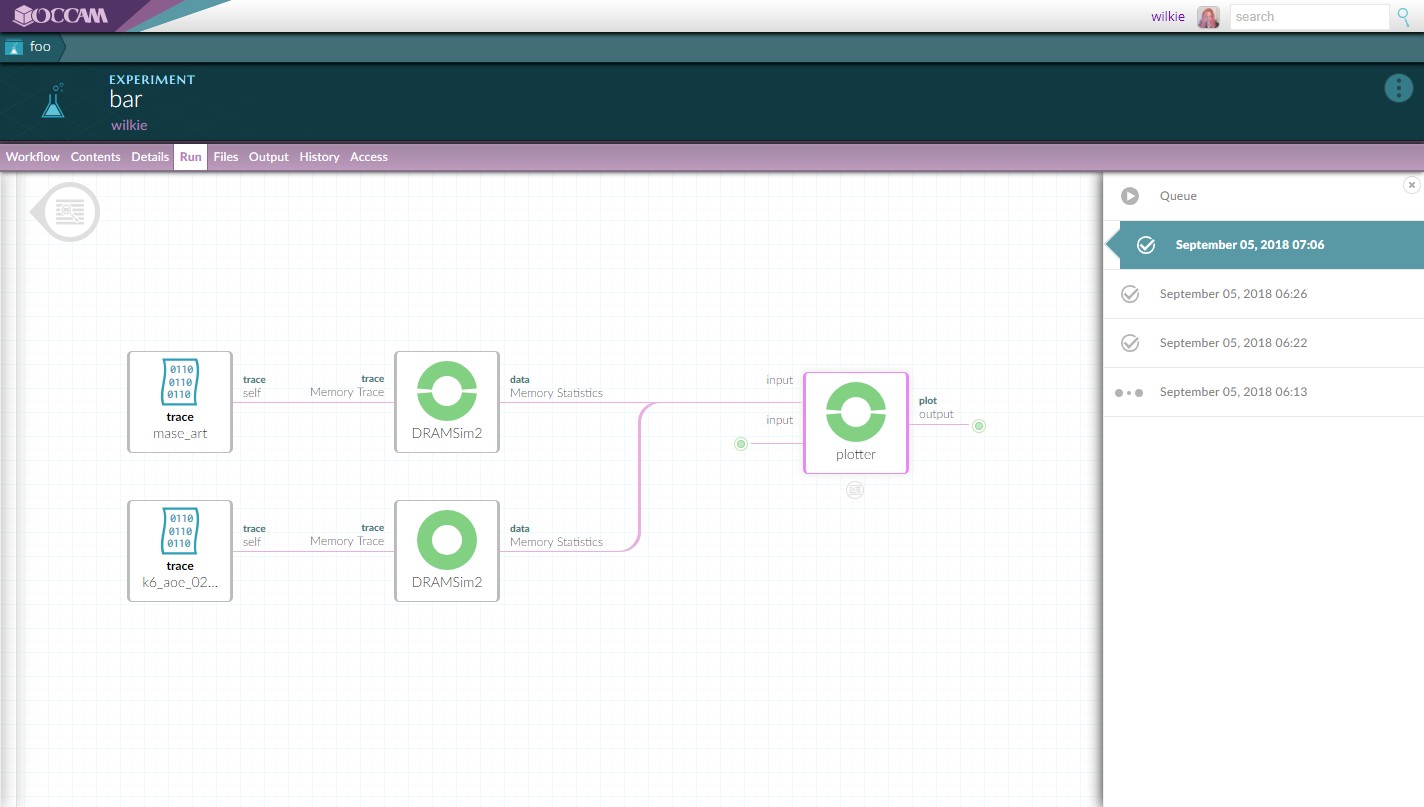
Upon running the workflow, you are treated to a view where you can see each node as it runs and inspect the runtime log for any currently running software. You can also interact with prior runs.
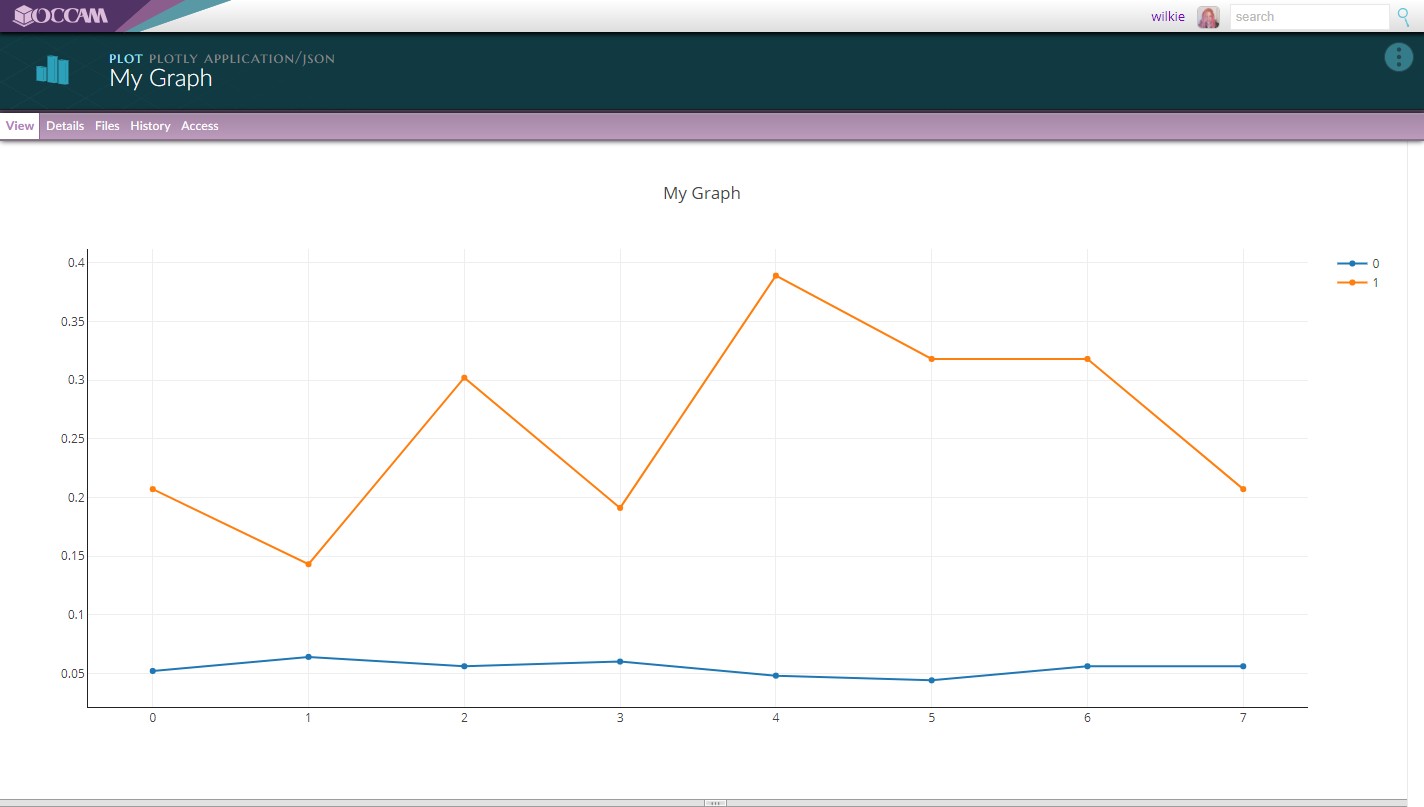
Your workflow may generate many different types of artifacts. In this case, our script generated a plot. We are using a widget to view that plot called plotly.js.
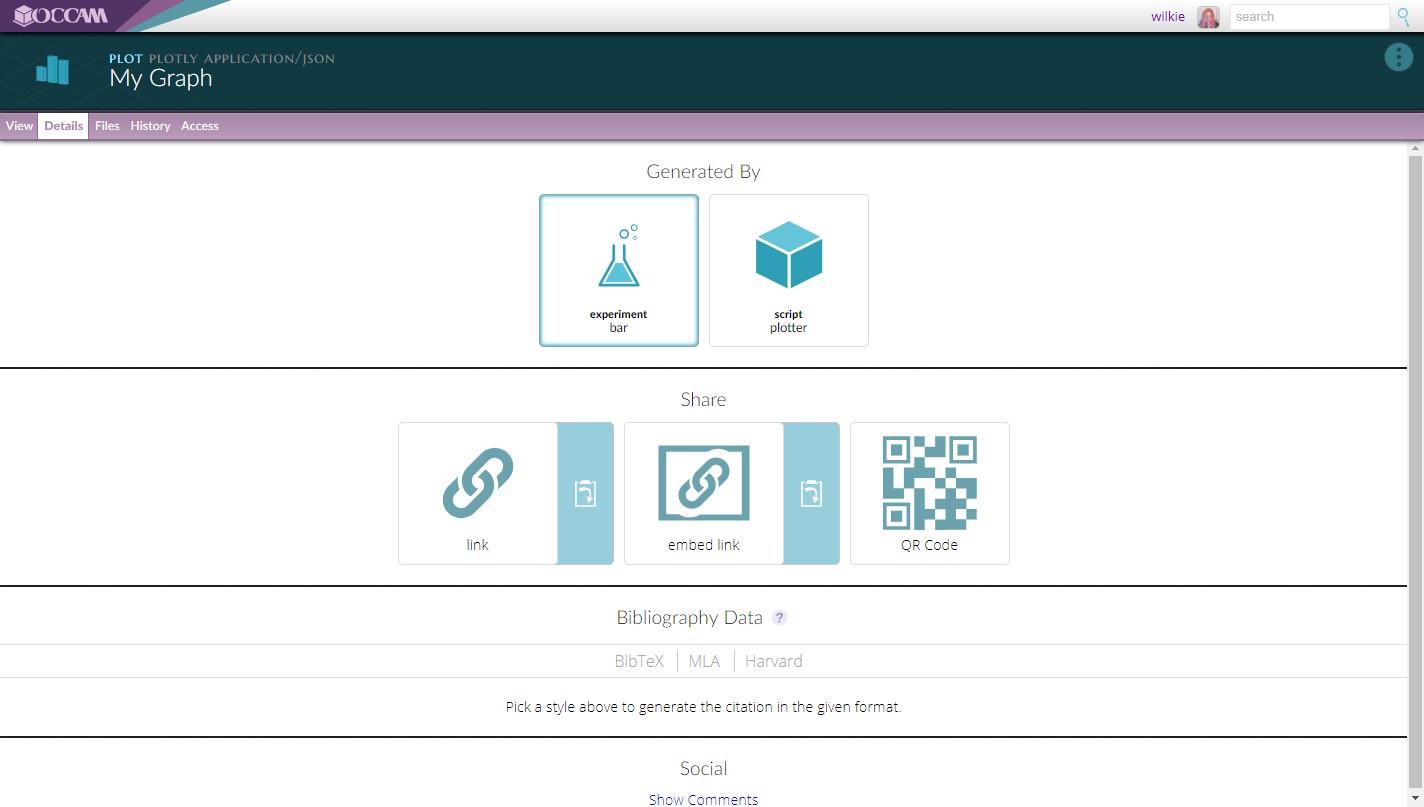
When you look at the metadata for this plot, you will find a link back to both our bespoke script that generated the plot from the data, and the overall experiment that holds the workflow itself. All generated output contains information about its provenance and origin.
When you create new software (or wrap an existing tool), you will provide a set of configuration options and metadata that describes what kind of inputs and outputs your software deals with. With this, the workflow editor knows what possible connections can be made, and what data it should expect gets generated when the software runs. The amount of metadata is fairly light. Just a few small tags and a JSON configuration schema, which you can see an example of here.